¶ Docker 应用
¶ 什么是 Docker
Docker 是一个可以用作开发和发布应用、部署应用的开源平台[1],你可以用它运行服务或者一段程序脚本,并且可以将运行的环境依赖封装为镜像保存起来便于你下次运行。
它还能为你隔离多个服务,比如你运行了一个搭建在 Ubuntu 操作系统之上的 Nginx 服务器,或是一个 CentOS 系统安装了 Python 环境并运行了 Flask 服务,你都可以将它们分别打包为不同的镜像,并作为独立的服务运行在同一个宿主机上。
这有些像虚拟机(虽然本质并不相同),在你的宿主机上运行其他操作系统,并在这些操作系统里面运行一些服务或者脚本。
¶ 安装
为了更快的理解 Docker 的用途和功能,我们先完成安装流程,Docker 支持多平台的安装[2]。
鉴于容器多用于服务化环境,我们这里选择 Linux - Ubuntu 作为安装 Docker 的操作系统,其他 Linux 发行版环境可以参考官网自行选择[3]。
Ubuntu 下我们使用 apt-get 作为安装工具直接获取 Docker 的二进制版本。
如果下面的命令遇到系统权限问题中止,可自行添加 sudo 提升用户权限后重试。
¶ 安装前的工作
- 更新
apt索引源并安装前提依赖。
$ apt-get update
$ apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
- 添加 Docker 的官方 GPG 秘钥。
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
验证指纹秘钥是否正确,通过下面的命令搜索 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 是否匹配。
$ apt-key fingerprint 0EBFCD88
pub rsa4096 2017-02-22 [SCEA]
9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88
uid [ unknown] Docker Release (CE deb) <docker@docker.com>
sub rsa4096 2017-02-22 [S]
- 设置源
$ add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
¶ 安装 Docker
完成上面的预处理工作后,直接运行下面的命令开始正式安装 Docker。
$ apt-get update
$ apt-get install docker-ce docker-ce-cli containerd.io
¶ 确认版本
安装成功后,先确认其版本(这一步可以作为命令行正常工作的测试证明)。
$ docker --version
Docker version 19.03.13, build 4484c46d9d
¶ 概念
Docker 安装完毕,在开始使用之前,需要分别认识几个角色,大致从结构[4]上了解这个工具。
¶ Docker Engine
Docker 采用客户端 - 服务端架构设计,这表示它会实现一个命令行客户端(CLI),我们大部分时间都是通过这个 CLI 发送网络请求(RESTful API)和 Docker 的后台进程(docker daemon)交互。客户端、API 和服务端程序构成在一起被统称为 Docker Engine[5]。
提供官方 Docker Engine 的结构图。
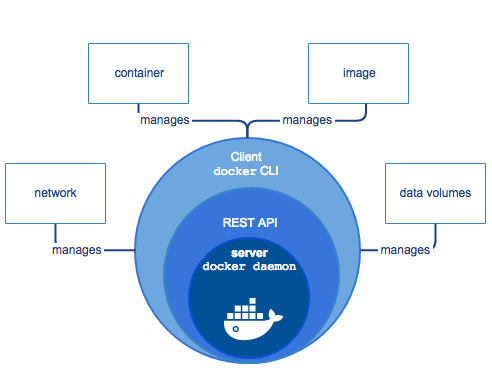
你会留意到,上图中还进一步细化了 image、container、data volumes 和 network 这些概念。
如果你之前使用过虚拟机,那么大体做过把一个虚拟机镜像(一个 iso 格式的文件)从某处下载到本机(Host),然后载入到 VMware 这样的虚拟机工具中运行。其实在这个流程中,你已经和好几个不同职能的构件打了交道,比如虚拟网卡、虚拟存储等,上面的这些概念在 Docker 中也同样存在。
¶ Docker 的架构
我们可以从使用流程上理解 Docker 的架构。
与虚拟机相似,试想下,如果你需要一个 Ubuntu 的操作系统环境,那么你就需要获取到镜像(image),那么首先你需要从某处下载这个镜像,这个某处在 Docker 生态中就是 Registry(一个私有或共有的镜像存储中心服务,存储着官方和社区贡献的基于不同操作系统、不同环境依赖的镜像)。
接下来你需要运行这个镜像,在虚拟机中这很好理解,VMware 会从 iso 压缩包中安装相应的系统然后运行,接着你会进入到该系统的可视化界面。但是在 Docker 中,这个运行流程变得更加纯粹和单一,你可能只是运行了一个后台程序(而不是多个),Docker 将这种运行中的状态称之为容器(container),也就是一个镜像的实例。

上图中的 docer pull 和 docker run 对应从 Registry 下载镜像和通过镜像运行对应操作系统环境这两个步骤,docker build 制作镜像的命令,我们在镜像小节可以学习到细节。
¶ 简单使用
下面我们使用 Docker 命令行客户端做一些基本的操作。
¶ 运行容器
- 首先从一个名为
ubuntu的镜像开始运行容器。
$ docker run -i -t ubuntu /bin/bash
Unable to find image 'ubuntu:latest' locally
latest: Pulling from library/ubuntu
da7391352a9b: Pull complete
14428a6d4bcd: Pull complete
2c2d948710f2: Pull complete
Digest: sha256:c95a8e48bf88e9849f3e0f723d9f49fa12c5a00cfc6e60d2bc99d87555295e4c
Status: Downloaded newer image for ubuntu:latest
root@8e4765ca5c0e:/#
docker run 是 Docker 的主要运行容器命令,-i 参数会进入交互式命令行模式,STDIN 会保持开启状态,监听用户的进一步指令,-t 参数会使 Docker 分配一个 pseudo-TTY 给用户,配合容器内的 /bin/bash 使用。
这一步会首先下载名为 ubuntu 的镜像到本地,我们没有指定版本,那么默认就是从官方的 Registry(Docker Hub) 下载 ubuntu:latest 镜像,下载完成后,会通过 /bin/bash 命令运行容器,运行成功后,命令提示符发生变化,我们的 Shell 环境已经从宿主机切换到容器的 Bash 环境。
- 查看已经下载到本地的镜像。
重新启动一个新的 Terminal,我们可以通过下面的命令查看已经下载到本地的ubuntu:latest镜像。
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest f643c72bc252 2 weeks ago 72.9MB
- 查看已经运行的容器。
通过下面的命令我们可以查看当前存在的容器列表,Docker 会为每个创建的容器分配独立的CONTAINER ID作为标识,也就是容器的hostname。
$ docker ps --all
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7cc2d9f71570 ubuntu "/bin/bash" 3 seconds ago Up 2 seconds
注意,这个时候我们容器的状态是 Up,如果此时我们从第一个 Terminal 中退出,那么命令提示符会切换回宿主机的 Shell,因为交互中断,容器也会进入到 Exited 状态。
¶ 其他有用的指令
对于运行中的容器,你还可以使用下面的基本指令。
-
停止运行的容器。
$ docker container stop <container_name|container_id> -
移除停止的容器
$ docker container rm <container_name|container_id>注意一般容器操作都需要先停止才能删除,如果你想直接删除,可以使用
docker container rm -f <container_name|container_id>强制移除。 -
对运行中的容器额外下发命令
比如单独创建一个交互式bashShell 到某个运行中的容器。$ docker exec -it <container_name|container_id> bash或者你还可以为某个运行中的容器额外设置环境变量。
$ docker exec -it -e VAR=1 <contaienr_name|container_id> bash
¶ 容器和虚拟机
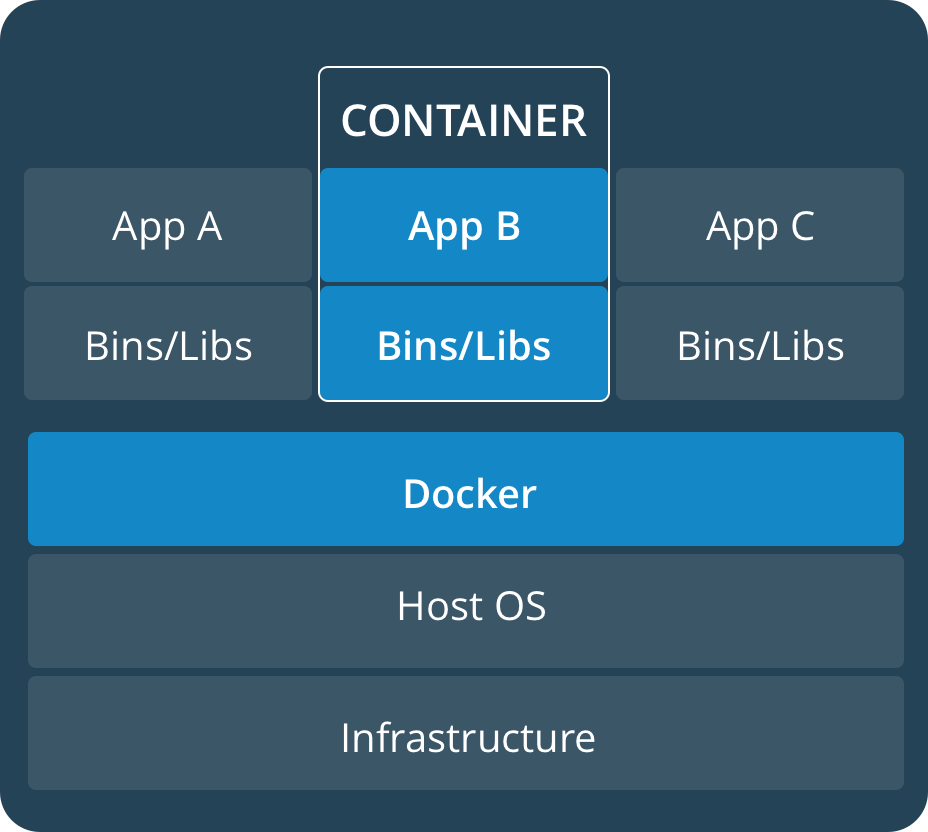
到目前为止,我们一直在使用虚拟机的概念去理解 Docker,那么这二者的区别[6]是什么呢?
简而言之,容器技术更加轻量,假设你的宿主机是 Linux,那么不同的容器之间会共享同一个 Linux 系统内核,容器分别运行在独立的进程中,与其他容器和宿主机的执行进程保持隔离。
而虚拟机则是运行了一个完整的操作系统,你可以将之视为一个取得了操作系统所有资源授权的用户拿着宿主机提供的资源实现了独立的操作系统功能,这意味着,你在虚拟机中运行的程序,会使宿主机承担更多的开销。
¶ 镜像
上一节我们使用 Docker 运行了基于 Ubuntu 的操作系统环境的容器,并通过 /bin/bash 指令在容器中实现了 Ubuntu 命令解释器的交互式体验。
但是这还远远不够,我们在工作中一定会遇到定制化容器的场景,比如一个团队想分别定制基于 Express.js 和 SpringBoot 的容器,那么一个 Ubuntu 系统肯定是不满足要求的,团队成员还需要分别安装 Node.js 和 Java 环境,并做很多业务定制的工作,这样定制容器的镜像就是一个必须要满足的需求了。
¶ 制作镜像
我们使用 Docker 官方的示例[7]去演示如何构建自己的镜像,首先通过 Git 获取到官方的示例仓库。
$ git clone https://github.com/dockersamples/node-bulletin-board
$ cd node-bulletin-board/bulletin-board-app
可以看到该目录下存在一个 Dockerfile 文件,这个文件描述了如何创建一个新的镜像。
$ cat Dockerfile
FROM node:current-slim
WORKDIR /usr/src/app
COPY package.json .
RUN npm install
EXPOSE 8080
CMD [ "npm", "start" ]
COPY . .
我们逐步观察镜像的构成内容。
-
FROM node:current-slim
当前Dockerfile指定node:current-slim镜像作为打底镜像,这意味着当前制作的镜像完全基于node:current-slim镜像做上层定制(这意味着所有人都可以基于一个社区或者官方提供的标准镜像去做上层修改,而不需要自己重新安装一遍基础环境)。 -
WORKDIR /usr/src/app
当前镜像默认所在的目录是/usr/src/app,这表示一旦该镜像运行成为容器,容器会自动进入这个路径中,这样开发者可以在一个自己指定的目录中存放一些配置文件。 -
COPY package.json .
拷贝当前宿主机/path/to/node-bulletin-board/bulletin-board-app目录下的package.json文件到镜像中的/usr/src/app下。 -
RUN npm install
运行 Node.js 的包管理工具 NPM 安装所有package.json中指定的 Node.js 项目依赖。 -
EXPOSE 8080
安装完毕依赖后,暴露镜像的 8080 端口,这意味着该镜像一旦运行成为容器,宿主机可以通过 8080 端口与容器通讯,自然也能找到容器中该端口运行的服务。 -
CMD [ "npm", "start" ]
指定镜像运行成为容器后的默认命令,我们上一节用/bin/bash作为进入ubuntu:latest镜像运行的容器后的指定命令。在这里,我们制作好的镜像运行成为容器后会默认运行npm start,这条命令会寻找package.json中描述的当前 Node.js 项目启动脚本,查看package.json中得知具体内容为node server.js。 -
COPY . .
该命令会拷贝所有/path/to/node-bulletin-board/bulletin-board-app下的 Node.js 源码文件到镜像/usr/src/app中。
理解了 Dockerfile 的内容后,我们使用下面的命令开始正式构建镜像。
$ docker build --tag bulletinboard:1.0 .
Sending build context to Docker daemon 45.57kB
Step 1/7 : FROM node:current-slim
---> 9ac9e9f30b2c
Step 2/7 : WORKDIR /usr/src/app
---> Running in 266813564f95
Removing intermediate container 266813564f95
---> 20d33d49fc42
Step 3/7 : COPY package.json .
---> 852ab2e63c38
Step 4/7 : RUN npm install
---> Running in d4cfe37404de
...
如果构建成功,通过 docker image ls 可以看到名为 bulletinboard:1.0 的镜像出现在列表中。
最后通过下面的命令创建容器。
$ docker run --publish 8000:8080 --detach --name bb bulletinboard:1.0
--publish 8000:8080 映射宿主机的 8000 端口到容器的 8080 端口,这意味着通过以 <protocol>://<ip>:<port> 形式的网络访问宿主机 8000 端口相当于直接访问到了容器的 8080 端口所在的服务(本案例中为上述 node server.js 启用的 Node.js 服务)。
--detach 表示以后台形式运行,不会像上述 /bin/bash 一样交互式的停留在 Terminal 前台等待用户输入。
--name bb 表示给创建的容器起名为 bb。
最后是创建当前容器所依赖的镜像名,格式是 <镜像名>:<镜像版本>。
上述命令运行成功后,一个基于 node:current-slim 环境的 Node.js 项目就可以通过宿主机的 8000 端口访问到了。
¶ 提交镜像到 Docker Hub
自定义的镜像创建成功后,可以通过上传到 Docker Hub 的方式分享,这样其他开发者可以通过 docker pull 获取到你的镜像,这有些像开源社区 Github 的运作方式。
首先创建 Docker Hub 的账号 并填写用户的 Docker ID,登录后先在本地做使用 docker tag 标签化将要上传的镜像(因为 Docker Hub 是以 <Your Docker ID>/<Repository Name>:<tag> 的格式识别不同用户名称空间下的镜像)。
$ docker tag bulletinboard:1.0 <Your Docker ID>/bulletinboard:1.0
然后就可以推送到 Docker Hub 了。
$ docker push <Your Docker ID>/bulletinboard:1.0
¶ 挂载卷
通过上面的步骤你可以做到通过 Docker 构建自定义服务的镜像,并且共享到 Docker Hub。你为团队贡献了一份 Node.js 技术栈的镜像,以后这个服务功能有更新只需要更改项目源码然后重新制作镜像,交付给运维同学写一个 docker run 的脚本就可以一键部署,看起来一切似乎都很美好。
但是其他后端的同学看到了这个用法就头疼了,他们照顾的服务不仅有业务服务,还有存储服务,有些稍微复杂的业务场景更使用了缓存和非关系型数据库,如果这些服务可以制作为镜像容器化,那么最关键的数据由谁管理呢?
Docker 提供了 volumes 和 bind mounts 两种方式做服务产生的数据持久化处理,前者有些像外挂式存储(比如你通过移动硬盘连接到某台电脑上拷贝数据,即使后来这台电脑本身出现了问题,移动硬盘中的数据也不会丢失)。后者依赖宿主机的文件目录结构,仅仅做了一层映射(就像你给某个路径做了快捷方式的访问入口)。
volumes 是官方较为推荐的方式[8],因为其完全由 Docker 自行管理,不需要额外借助宿主机的文件目录,而且 volumes 在容器间共享,数据迁移备份、还原,远端云存储,数据加密和跨平台处理均有优势。
最为推荐的理由是,volumes 的技术实现独立于容器生命周期之外,换言之,一个使用到 volumes 的容器不会因多了 volumes 而增加体积,容器本身的销毁和重建都不会影响已经存在的 volumes。
下图简单的描述了 volumes 和 bind mounts 间的区别。

¶ 使用卷存储
既然 volumes 有如此多的优势,我们先来查看其功能和使用方法。
- 创建 volumes
创建 volumes 可以简单指定名称即可,下面创建了一个名为my-vol的存储卷。
$ docker volume create my-vol
- 列出所有的 volumes
$ docker volume ls
local my-vol
- 查看某个 volumes 详细信息
$ docker volume inspect my-vol
[
{
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/my-vol/_data",
"Name": "my-vol",
"Options": {},
"Scope": "local"
}
]
- 移除某个 volumes
$ docker volume rm my-vol
¶ 配合容器使用卷
正常情况下,我们需要配合容器运行使用挂载卷。
$ docker run -d \
--name devtest \
-v myvol2:/app \
nginx:latest
上面的命令指定镜像为 nginx:latest,通过后台形式创建了一个名为 devtest 的容器,并且创建名为 myvol2 的 volumes 挂载卷,映射到容器中的目录结构为 /app。
这里需要留意 -v 参数具备多种语义[9]。上述命令创建的容器中 /app 目录如果本就不存在任何内容,那么 myvol2 会实时的映射到该路径中,这意味着,devtest 容器创建后在容器内的 /app 目录下产生的任何数据都将实时同步到 myvol2 中。
当然,你会想到另一种场景是,如果 devtest 容器创建后在 /app 内原本就存在内容(一些文件和目录), 这些内容会直接拷贝到名为 myvol2 的挂载卷中。
最后你也许还会疑问,如果本身 myvol2 就已经存在而不是新创建的,而且本身就有内容,这个时候会怎么样呢?其实很简单,Docker 不会舍弃原本就存在于卷中的数据,如果 devtest 是新产生的容器并且在 /app 下已经存在了内容,此时 -v myvol2:/app 会直接使用 myvol2 中已经存在的数据覆盖新创建的 devtest 中 /app 下的所有内容。
¶ 备份
通过上面的容器使用卷我们可以理解到,volumes 会被 Docker 独立处理存储,不会因为任何与之关联的容器销毁而丢失数据。
一般生产环境下的服务数据会使用独立的备份脚本多点冗余备份,那么在 Docker volumes 中的数据也可以单独打包拷贝出来。
$ docker run -v /dbdata --name dbstore ubuntu /bin/bash
上述命令创建了一个匿名的挂载卷,映射容器 dbstore 中 /dbdata 路径下所有文件内容,下面我们会针对该目录下的内容做备份。
$ docker run --rm --volumes-from dbstore -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /dbdata
上述命令创建了一个新的容器,--rm 会在该容器退出后自动删除容器,不会保留为 Exited 状态。该容器会从名为 dbstore 的容器中共享同一份挂载卷,--volumes-from 会使 dbstore 容器中的挂载点 /dbdata 挂载于新容器的同样路径下。
-v $(pwd):/backup 会把宿主机的当前路径映射到新创建容器中的 /backup 目录中,结合最后在新创建容器中的指令 tar cvf /backup/backup.tar /dbdata 会将已经共享挂载到当前容器下 /dbdata 的数据打包到 /backup 目录下并命名为 backup.tar,此时因为 /backup 已经被映射到宿主机的当前目录下,因此 /backup/backup.tar 压缩包从容器中映射到宿主机当前目录下,完成了从 dbstore 容器中挂载卷的备份。
¶ 还原
承接上一小节,我们继续把备份数据 backup.tar 在新的容器中还原。
$ docker run -v /dbdata --name dbstore2 ubuntu /bin/bash
上述命令基于 ubuntu 镜像创建了名为 dbstore2 的容器,并且将 dbdata 映射在新的匿名挂载卷中。
$ docker run --rm --volumes-from dbstore2 -v $(pwd):/backup ubuntu bash -c "cd /dbdata && tar xvf /backup/backup.tar --strip 1"
接着生成一个退出后就会被回收的新容器,该容器共享了 dbstore2 的挂载点 /dbdata,同时映射宿主机当前路径到容器内的 /backup 中,因为映射关系建立,宿主机当前目录下的 backup.tar 会直接创建在当前容器中的 /backup 下。
最后当前容器执行了 bash -c "cd /dbdata && tar xvf /backup/backup.tar --strip 1",该命令 cd 到 /dbdata 目录下随后解压缩 /backup/backup.tar 压缩包中的所有内容,这样原先在宿主机当前目录下的备份文件 backup.tar 中的内容就被还原到了当前容器的 /dbdata 目录下,又因为当前容器与容器 dbstore2 的共享卷关系,当前容器 /dbdata 目录下解压缩的全部内容被共享到 dbstore2 的 /dbdata 目录下。
¶ 网络
上一节我们通过 volumes 对容器内产生的内容进行持久化,在实际场景中的数据存储环节貌似得到了解决。不过实际服务和数据库在生产环境中通常是部署在不同的容器中,那么让业务服务器(比如 Flask、Express.js)和承载数据库服务的容器通讯就成为了必不可少的功能。
当然 Docker 提供了完善的网络系统用以解决容器间网络通讯问题。
¶ 网络驱动
Docker 通过几个不同的驱动[10]管理网络模块。
-
bridge
默认的网络驱动,一般用于独立的容器间通讯。 -
host
容器直接使用宿主机的网络环境。当你不希望当前容器依赖的网络和 Host 宿主机的网络隔离,但是又希望进程、存储、内存等系统资源和宿主机隔离时推荐使用。 -
overlay
用于容器集群间通讯,也可用于独立容器间通讯。overlay 驱动一般用于解决规模化微服务集群、多个 docker daemon 间通讯场景。 -
macvlan
该驱动可以为容器分配 MAC 地址,在网络访问中让容器显示为一台真正的物理设备。 -
none
禁用容器的网络,一般该选项配合自定义网络驱动使用。 -
Network Plugins[11]
可以通过 Docker Hub 或第三方供应平台自行配置容器的网络插件。
¶ 容器间通讯实践
下面我们来熟悉下常用的网络操作,并通过默认的 bridge 驱动建立容器间通讯[12]。
- 查看目前已经存在的网络列表
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
17e324f45964 bridge bridge local
6ed54d316334 host host local
7092879f2cc8 none null local
- 运行两个
alpine容器
$ docker run -dit --name alpine1 alpine ash
$ docker run -dit --name alpine2 alpine ash
alpine 是一种特殊的 Linux 操作系统镜像,它由社区定制,相较一般的 CentOS 或 Ubuntu,它几乎只保留了内核和可用的核心命令,非常精简。而 ash 是 alpine 中的命令解释器,功能类似 bash。
我们使用 -dit 的形式运行,会直接把交互式 ash 命令解释器等待输入的状态放到后台。
- 查看有哪些容器连接到了 bridge 网络中
$ docker network inspect bridge
[
{
"Name": "bridge",
"Id": "17e324f459648a9baaea32b248d3884da102dde19396c25b30ec800068ce6b10",
"Created": "2017-06-22T20:27:43.826654485Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {
"602dbf1edc81813304b6cf0a647e65333dc6fe6ee6ed572dc0f686a3307c6a2c": {
"Name": "alpine2",
"EndpointID": "03b6aafb7ca4d7e531e292901b43719c0e34cc7eef565b38a6bf84acf50f38cd",
"MacAddress": "02:42:ac:11:00:03",
"IPv4Address": "172.17.0.3/16",
"IPv6Address": ""
},
"da33b7aa74b0bf3bda3ebd502d404320ca112a268aafe05b4851d1e3312ed168": {
"Name": "alpine1",
"EndpointID": "46c044a645d6afc42ddd7857d19e9dcfb89ad790afb5c239a35ac0af5e8a5bc5",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
上面打印的内容包含了 IP 和网关的信息,我们主要留意 Containers 属性的内容,这正是我们刚刚创建的两个基于 alpine 镜像的容器实例所分配的 IP 地址。
其中容器 alpine1 分配到的地址为 172.17.0.2,alpine2 分配到的地址为 172.17.0.2。
- 连接到容器中
$ docker attach alpine1
/ #
attach 指令可以帮助我们回到后台运行的容器中,注意命令提示符发生变化,表示我们已经处于容器 alpine1 中。
接着查看容器内的网络信息。
# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
27: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
注意第二个网卡信息,172.17.0.2 和刚才我们使用 docker network ls 查看到的信息是一致的。
- 测试网络连通
# ping -c 2 baidu.com
PING google.com (172.217.3.174): 56 data bytes
64 bytes from 172.217.3.174: seq=0 ttl=41 time=9.841 ms
64 bytes from 172.217.3.174: seq=1 ttl=41 time=9.897 ms
--- baidu.com ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 9.841/9.869/9.897 ms
我们通过 ping -c 2 发送两个数据包请求到 baidu.com,发现容器 alpine1 是可以连通到互联网的。
- 测试容器间连通
# ping -c 2 alpine2
ping: bad address 'alpine2'
我们接着发送数据包到 alpine2 这个容器 Host,发现是无法连通的。这是当然的,目前我们还没有针对两个容器间通讯做任何设置呢。
- 创建 bridge 网络
我们先从alpine1的容器环境中离开,按住CTRL,然后连续输入p和q,这样容器不会像CTRL+d一样退出,当前的运行状态可以继续保留在后台中。
接着我们开始创建 bridge 网络吧。
$ docker network create --driver bridge alpine-net
创建成功后再次查看网络列表,发现已经自定义的 bridge 网络已经出现了。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
e9261a8c9a19 alpine-net bridge local
...
紧接着查看 alpine-net 的细节信息。
$ docker network inspect alpine-net
[
{
"Name": "alpine-net",
"Id": "e9261a8c9a19eabf2bf1488bf5f208b99b1608f330cff585c273d39481c9b0ec",
"Created": "2017-09-25T21:38:12.620046142Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
注意网关信息 IPAM.Config.Gateway 为 172.18.0.1。
- 以自定义 bridge 模式运行容器
$ docker run -dit --name alpine3 --network alpine-net alpine ash
$ docker run -dit --name alpine4 --network alpine-net alpine ash
$ docker run -dit --name alpine5 alpine ash
$ docker run -dit --name alpine6 --network alpine-net alpine ash
新创建的容器都已经运行。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
156849ccd902 alpine "ash" 41 seconds ago Up 41 seconds alpine6
fa1340b8d83e alpine "ash" 51 seconds ago Up 51 seconds alpine5
a535d969081e alpine "ash" About a minute ago Up About a minute alpine4
0a02c449a6e9 alpine "ash" About a minute ago Up About a minute alpine3
- 查看
alpine-net信息
$ docker network inspect alpine-net
[
{
"Name": "alpine-net",
"Id": "e9261a8c9a19eabf2bf1488bf5f208b99b1608f330cff585c273d39481c9b0ec",
"Created": "2017-09-25T21:38:12.620046142Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {
"0a02c449a6e9a15113c51ab2681d72749548fb9f78fae4493e3b2e4e74199c4a": {
"Name": "alpine3",
"EndpointID": "c83621678eff9628f4e2d52baf82c49f974c36c05cba152db4c131e8e7a64673",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
},
"156849ccd902b812b7d17f05d2d81532ccebe5bf788c9a79de63e12bb92fc621": {
"Name": "alpine6",
"EndpointID": "058bc6a5e9272b532ef9a6ea6d7f3db4c37527ae2625d1cd1421580fd0731954",
"MacAddress": "02:42:ac:12:00:04",
"IPv4Address": "172.18.0.4/16",
"IPv6Address": ""
},
"a535d969081e003a149be8917631215616d9401edcb4d35d53f00e75ea1db653": {
"Name": "alpine4",
"EndpointID": "198f3141ccf2e7dba67bce358d7b71a07c5488e3867d8b7ad55a4c695ebb8740",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
我们可以看到,alpine3、alpine4 和 alpine6 这三台容器已经都关联到了 alpine-net 网络中。
- 再次测试容器间网络连通
$ docker container attach alpine3
# ping -c 2 alpine4
PING alpine2 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.085 ms
64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.090 ms
--- alpine4 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.085/0.087/0.090 ms
# ping -c 2 alpine6
PING alpine4 (172.18.0.4): 56 data bytes
64 bytes from 172.18.0.4: seq=0 ttl=64 time=0.076 ms
64 bytes from 172.18.0.4: seq=1 ttl=64 time=0.091 ms
--- alpine6 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.076/0.083/0.091 ms
# ping -c 2 alpine3
PING alpine1 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.026 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.054 ms
--- alpine3 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.026/0.040/0.054 ms
# ping -c 2 alpine5
ping: bad address 'alpine5'
可以看到,这一次 alpine3 可以连通到处于同一网络 alpine-net 内的 alpine4 和 alpine6,但是无法连通到 alpine5,符合预期。
- 移除所有容器和自定义的 bridge 网络
$ docker container stop alpine1 alpine2 alpine3 alpine4 alpine5 alpine6
$ docker container rm alpine1 alpine2 alpine3 alpine4 alpine5 alpine6
$ docker network rm alpine-net
¶ iptables
Docker 通过更改 iptables 规则实现网络隔离[13]。
本小节内容等待进一步完善
¶ 安全性
还记得在镜像一节中我们依赖 node:current-slim 定制的 Node.js 服务么?在 Dockerfile 中我们最终把镜像的 8080 端口暴露给宿主机,运行容器的时候再通过 -p 8000:8080 的方式绑定 Host 和容器的端口,这样用户就可以通过宿主机的 IP 地址和 8000 端口访问到容器内的 8080 端口服务了。
但是这样的做法存在一个问题,因为 Docker 更改了 iptables 规则,导致 ufw 这样的 iptables 应用层防火墙工具失效,这意味着,你通过容器暴露到宿主机的所有端口,即使没有和宿主机端口绑定,也会直接暴露到公网。
实际生产场景中,不是所有的服务都需要提供到公网环境中,很多后台数据中心和离线服务都不需要(也不可以)直接被用户访问到,也不能够被 nmap 这样的网络扫描工具察觉到,那么在不破坏 Docker 本身对 iptables 规则的定制前提下,隐藏容器暴露的端口成为了提升生产环境部署安全性的必要措施。
@chaifeng 开源的 ufw-docker[14] 可以解决上述问题,作者通过修改 /etc/ufw/after.rules 处理链规则保留了 Docker 对路由表的处理并支持了 UFW 管理外部网络对容器的访问。
具体细节可以查看 解决 ufw 和 docker 的问题。
如果不希望手动修改,可以直接安装作者开源的 ufw-docker 工具 进行规则管理。
wget -O /usr/local/bin/ufw-docker \
https://github.com/chaifeng/ufw-docker/raw/master/ufw-docker
chmod +x /usr/local/bin/ufw-docker
然后直接通过命令修改上述 /etc/ufw/after.rules 文件。
ufw-docker install
安装成功后重启,我们发现之前的 Node.js 服务 8000 端口已经无法在外网访问了,符合预期。我们来使用 ufw-docekr 添加对该服务容器端口的放行规则。
ufw-docker allow <container_name> 8080
注意上面的命令会开放容器服务的 8080 端口,即为宿主机的 8000 端口,这样相比于 ufw 工具会同时开放宿主机和容器端口的行为而言更加合理。
最后可以通过以下命令查看当前的防火墙规则。
ufw-docker list <container_name>
# or
ufw status
至此容器的服务端口安全开放问题得到解决。
¶ 编排和配置化
¶ 服务集群化
¶ Docker Swarm
本小节内容等待进一步完善
¶ Kubernetes
本小节内容等待进一步完善
¶ 生态能力
¶ 持续集成
¶ 私有镜像服务
Docker 提供一种可以存储和分发镜像的平台称为 Registry[15],该平台本身亦如同容器一样可以以 Docker 的方式运行。
不同于 Docker Hub 的服务形式,Registry 的目的是构建属于适合你自己的私有镜像存储功能。
¶ 构建和使用
依赖官方开源提供的 registry:2 镜像,我们可以从中方便的运行容器服务。
docker run -d -p 5000:5000 --name registry registry:2
上述命令使我们拥有了一个运行在 5000 端口的镜像托管服务,我们接着推送镜像到上面看看。
先从 Docker Hub 拉取 ubuntu 的镜像到本地。
docker pull ubuntu
然后通过 tag 指令重命名本地 ubuntu 镜像的名称。
docker image tag ubuntu localhost:5000/myfirstimage
需要注意,上面命令中之所以重命名为 localhost:5000 的前缀是因为 Docker 对镜像的命名方式[16]决定了镜像的拉取和推送标识方式均以 <domain:port>/<image_owner_name>/<image_name>:<image_version> 的格式展示。
用 docker pull ubuntu 为例理解,其完整的命令为 docker pull docker.io/library/ubuntu:latest。
重命名后,可以直接推送到私有镜像服务中。
docker push localhost:5000/myfirstimage
其他能够访问到该服务的客户端可以用类似的方式拉取该镜像。
docker pull localhost:5000/myfirstimage
¶ 支持 HTTPS
上一节的方法在生产环境中当然是无法使用的,首先我们需要让外部客户端可以访问到主机,而不是用 locahost 的方式做单机模拟。
鉴于 Docker 对 Registry 生产服务的限制,如果要满足外部访问,首先需要对主机的域名支持 TLS[17]。这里官方推荐使用 Let’s Encrypt(一个开源的 CA 提供商)生成主机的私钥和证书。
-
购买主机和域名
首先你需要获取一台拥有公网 IP 的主机服务器和相关联的域名(假设主机为 Ubuntu 操作系统环境,域名为foobar.com)。 -
安装 letsencrypt
因为 Let’s Encrypt 脚本依赖 Python 实现,而 Ubuntu 较新版本的操作系统都预装了 Python3,所以这里我们只需要安装 pip(Python 的包管理工具)。
apt install -y python3-pip
- 生成私钥和证书
letsencrypt命令会提示你输入一个邮箱账号绑定 TLS 服务。
letsencrypt certonly --standalone -d foobar.com
成功后你会在操作系统下面的两个目录中找到证书文件和私钥文件。
/etc/letsencrypt/live/foobar.com/fullchain.pem # 证书
/etc/letsencrypt/live/foobar.com/privkey.pem # 私钥
- 映射证书和私钥文件到 Registry 服务。
在你的项目目录下,创建一个存储证书和私钥用的新目录,并把相应的证书和私钥文件拷贝过来。
mkdir certs
cp /etc/letsencrypt/live/foobar.com/fullchain.pem certs/foobar.com.crt
cp /etc/letsencrypt/live/foobar.com/privkey.pem certs/foobar.com.key
然后重新运行 Registry 服务,并把 certs 目录映射到容器内部。
$ docker run -d \
--restart=always \
--name registry \
-v "$(pwd)"/certs:/certs \
-e REGISTRY_HTTP_ADDR=0.0.0.0:443 \
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/foobar.com.crt \
-e REGISTRY_HTTP_TLS_KEY=/certs/foobar.com.key \
-p 443:443 \
registry:2
上面的命令通过环境变量重新定义运行服务的端口为 443(而不是之前的 5000),并把 certs 目录中的证书和私钥文件提供给容器使用。
- 测试已经支持 TLS 的 Registry 私有镜像服务
我们这里从 Docker Hub 拉取一个ubuntu:16.04镜像做测试,往私有镜像服务中推送。
$ docker pull ubuntu:16.04
$ docker tag ubuntu:16.04 foobar.com/my-ubuntu
$ docker push foobar.com/my-ubuntu
推送成功后,在另外的客户端重新获取。
$ docker pull foobar.com/my-ubuntu
至此我们已经解决了外部访问的安全限制。
¶ 用户授权
到了上一节,我们虽然可以从外部访问到私有镜像服务,但是这意味着任何人都可以往 foobar.com 这个域名的 443 服务推送镜像,这一节我们就通过官方提供的原生授权方式解决该问题。
Docker 使用 Apache 工具 htpasswd 生成账户和密码做简单访问限制。
- 生成账户和密码文件
在项目中创建auth目录,运行htpasswd命令生成密码和关联的用户文件。
mkdir auth
htpasswd -Bbn testuser testpassword > auth/htpasswd
- 重新部署 Registry 服务
这里为了便于下一步授权理解,我们改为 5000 端口启动容器。
$ docker container stop registry
$ docker run -d \
--restart=always \
--name registry \
-p 5000:5000 \
-v "$(pwd)"/auth:/auth \
-e "REGISTRY_AUTH=htpasswd" \
-e "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm" \
-e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd \
-v "$(pwd)"/certs:/certs \
-e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/foobar.com.crt \
-e REGISTRY_HTTP_TLS_KEY=/certs/foobar.com.key \
registry:2
- 登录授权
$ docker login foobar.com:5000
之后就可以如同往常步骤一样推送和拉取私有镜像了。
- 使用 Compose file 管理部署
我们可以把第 3 步以docker-compose.yml文件形式配置化。
registry:
restart: always
image: registry:2
ports:
- 5000:5000
environment:
REGISTRY_HTTP_TLS_CERTIFICATE: /certs/foobar.com.crt
REGISTRY_HTTP_TLS_KEY: /certs/foobar.com.key
REGISTRY_AUTH: htpasswd
REGISTRY_AUTH_HTPASSWD_PATH: /auth/htpasswd
REGISTRY_AUTH_HTPASSWD_REALM: Registry Realm
volumes:
- /path/data:/var/lib/registry
- /path/certs:/certs
- /path/auth:/auth
然后使用 docker-compose 命令部署。
docker-compose up -d
¶ RESTful API
本小节内容等待进一步完善
¶ 图形界面服务
¶ 监控
本小节内容等待进一步完善
¶ Docker 原理
在上一章接触并使用 Docker 完成了诸如持续集成、服务化部署和私有镜像托管等应用功能后,我们尝试思考下,如果换做我们自己,如何借助 Linux 操作系统的生态能力实现容器呢?
¶ 资源隔离
Docker 依赖 Linux namespaces[18] 技术实现了资源隔离,你可以通过 Linux 的手册查看该功能的介绍。
$ man namespaces
这里的资源可以抽象为我们在使用容器运行服务后依赖的完整操作系统生态供给,例如独立的进程、独立的网卡和独立的挂载点等概念。
不同于宿主机运行的其他进程,容器进程通过 namespaces 实现了独立且隔离的操作系统环境,借助系统调用接口 clone,通过参数控制具体隔离的内容,可以从下面几个维度选择需要隔离的资源。
- 主机 UTS(Unix Time-sharing System)
传参CLONE_NEWUTS,可以隔离主机名和域名 - 进程号 PID(Process ID)
传参CLONE_NEWPID,可以隔离进程号 - 进程间通讯 IPC(Inter-Process Communication)
传参CLONE_NEWIPC,可以隔离信号量、消息队列、共享内存、Socket 和 Stream - 网络 Network
传参CLONE_NEWNET,可以隔离网络设备和端口 - 挂载点 Mount
传参CLONE_NEWNS,可以隔离文件系统的挂载点
参考 GopherCon UK 发布的 Let's write one in Go from scratch[19],我们可以通过关键逻辑理解 namespaces 具体如何实现基本资源隔离。
¶ UTS(Unix Time-sharing System)
依赖 Go 实现下方初步逻辑,调用系统接口 clone,传入参数 CLONE_NEWUTS 可以实现主机名的隔离。
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
default:
panic("what?")
}
}
func run() {
fmt.Printf("running %v\n", os.Args[2:])
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
保存上方逻辑为 main.go,运行下面的命令编译执行 go 代码,使用 /bin/bash 作为 clone 接口新开进程的解释交互环境,在新进程的 Bash 环境中更改 hostname,然后退出当前会话,可以发现被更改的主机名无法影响到宿主机的 hostname,从而实现主机名的隔离。
$ go run main.go run /bin/bash
running [/bin/bash]
# hostname
jovi.archer
# hostname foobar
# hostname
foobar
# exit
$ hostname
jovi.archer
¶ PID
在实现进程号隔离之前,我们需要了解 Linux 关于进程的一些信息。
如果你使用过 ps -ef 命令查看当前操作系统运行的进程,就会发现下面两个特殊的进程。
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 22:05 ? 00:00:01 /sbin/init
root 2 0 0 22:05 ? 00:00:00 [kthreadd]
其中一个是 PID 为 1 的 /sbin/init 进程,该进程会执行系统初始化任务,另一个 kthreadd 进程会调度其他内核进程。
如果你还使用过 pstree 指令,就可以看到一个非常形象的进程树打印在终端中,大致长这样。
systemd─┬─accounts-daemon─┬─{gdbus}
│ └─{gmain}
├─acpid
├─agetty
├─atd
├─containerd─┬─containerd-shim─┬─v2ray───7*[{v2ray}]
│ │ └─9*[{containerd-shim}]
│ └─8*[{containerd}]
├─cron
├─dbus-daemon
├─dockerd───7*[{dockerd}]
├─2*[iscsid]
├─lvmetad
├─mdadm
├─polkitd─┬─{gdbus}
│ └─{gmain}
├─rsyslogd─┬─{in:imklog}
│ ├─{in:imuxsock}
│ └─{rs:main Q:Reg}
├─snapd───8*[{snapd}]
├─sshd───sshd───bash
├─systemd───(sd-pam)
├─systemd-journal
├─systemd-logind
├─systemd-timesyn───{sd-resolve}
└─systemd-udevd
可以留意到,所有进程都被系统服务管理器 systemd 启动,其中 containerd 就是 Docker 产生的进程名,而所有的容器示例,都被名为 containerd-shim 的进程管理,与宿主机的进程隔离。
那么 Docker 是如何实现与宿主机的进程隔离呢?我们对刚才的 Go 代码继续添加 namespaces 中提及的进程隔离所依赖的系统调用接口 clone 的 CLONE_NEWPID 参数,并新增一个 Child 进程方便观察结果。
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("what?")
}
}
func run() {
fmt.Printf("running %v\n", os.Args[2:])
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID,
}
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
func child() {
fmt.Printf("running %v as pid: %d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
此时重新运行 go run main.go run /bin/bash 进入到进程的交互解释环境,输入 ps 会看到,该进程中已经无法输出宿主机的其他进程了。
¶ IPC
¶ Network
¶ 挂载点
¶ cgroup
¶ 存储驱动
¶ Union FS
Docker overview # Docker architecture | Docker Documentation ↩︎
Orientation and setup # Containers and virtual machines | Docker Documentation ↩︎
Use volumes # choose-the--v-or---mount-flag | Docker Documentation ↩︎
Networking with standalone containers | Docker Documentation ↩︎
chaifeng/ufw-docker: To fix the Docker and UFW security flaw without disabling iptables ↩︎
Golang UK Conf. 2016 - Liz Rice - What is a container, really? Let's write one in Go from scratch ↩︎